Run Azurite without disk persistence to simplify test clean-up
Azurite is an open-source emulator for the Azure Storage service, supporting blobs, queues, and tables. It’s cross-platform, simple to set up, and replaces the older Windows-only Azure Storage Emulator. Azurite is very easy to use and can run in a variety of scenarios: on your local machine, in Docker, in WSL, and on a CI just to name a few. It’s a Node.js JavaScript application that can run independently in Node.js or the VS Code extension host.
Overall, since Azurite gained Table storage support in 2021, it’s been my go-to for testing NuGet Insights changes locally. NuGet Insights stores all of its intermediate state and output data in Azure Storage, leveraging the blob, queue, and table API.
One pain point I’ve had is handling test clean-up for integration tests that run against Azurite. If you run your tests over and over against Azure Storage (be it Azurite, the legacy emulator, or live Azure Storage), you’ll accumulate a bunch of leftover test files that serve no purpose and need to be cleaned up by some other process (manual or automated).
Well, Azurite is open source and I decided to open a pull request to fix this pain point! My PR was merged and it’s now available in the released version of Azurite, as of version 3.28.0 (released on November 23rd, 2023).
I present --inMemoryPersistence, a new option in Azurite that disables all disk-based persistence and makes the
emulator only store data in-memory! Test clean-up is as simple as terminating the Azurite process.
In the future, I plan on blogging about how you can use Azurite in your CI runs to get great integration testing with Azure Storage without the need for real Azure credentials or any concern about test clean-up. For now, let’s just cover the new Azurite feature in detail.
Improved performance
When running only in-memory, Azurite spends less time handling API requests. This is because it does not need to wait on a disk IO operation before returning the API response to the caller. For my use case in NuGet Insights, this was particularly noticeable in the queue service where a disk write was needed for message enqueue (writing the queue message content to the extent store) and dequeue (reading message content from disk). This made some of my end-to-end tests that perform a lot of enqueues and dequeues go from ~55 seconds to run down to ~21 seconds. Yay!
I wrote a benchmark for blob, queue, and table APIs to demonstrate the improved performance.
| Persistence | Categories | Mean | Error | StdDev | Ratio |
|---|---|---|---|---|---|
| Disk | Blob | 5,853.8 μs | 47.17 μs | 70.61 μs | 1.00 |
| Memory | Blob | 1,755.6 μs | 16.05 μs | 24.02 μs | 0.30 |
| Disk | Queue | 5,463.5 μs | 78.72 μs | 117.83 μs | 1.00 |
| Memory | Queue | 1,556.3 μs | 14.96 μs | 22.39 μs | 0.28 |
| Disk | Table | 957.4 μs | 8.49 μs | 12.44 μs | 1.00 |
| Memory | Table | 967.8 μs | 9.94 μs | 14.57 μs | 1.01 |
This shows Blob and Queue operations can be about 3 times faster when using --inMemoryPersistence 🔥.
Some simple, common write operations were selected in the benchmark for each service but it goes to show that blob and queue operations are significantly faster without needing to write their content to disk. The Table API isn’t any faster because no disk IO is done as part of the API request since all of the data is stored in LokiJS’s in-memory structures.
Note that your tests may not be 3 times faster when using --inMemoryPersistence since a variety of factors are at
play, such as what the bottleneck is for your particular test suite (perhaps it’s IO unrelated to Azure Storage).
The benchmark is meant to show some significant change in performance but not tell you exactly how much faster your
particular test suite will be when using --inMemoryPersistence. Enough warranty? Okay!
Let’s dive in a little to how Azurite uses disk persistence today and how the new in-memory persistence works.
Disk-based persistence in Azurite (existing default behavior)
Currently, Azurite uses two forms of persistence. In other words, when blob, queue, or table data comes in through the storage REST APIs, the information is stored in one of two ways. First, structured data (referred to as metadata in the codebase) is stored using a JavaScript library called LokiJS. JavaScript objects are added to a LokiJS in-memory store. Second, binary content is stored in data files on disk called “extents”.
Blob metadata, queue metadata, and all table data are stored in LokiJS. This allows sorting, filtering, paging, and other operations you would expect from a database. LokiJS’s database operations are performed fully in-memory, meaning all of the Azurite metadata stored in LokiJS will be in-memory at once. However, data is periodically persisted to disk allowing some recovery if the Azurite process were to crash. Right now this persist step happens every 5 seconds in the background (not as part of an Azure Storage REST API).
Blob content and queue message content are both stored in extents. Metadata about the extents is stored in LokiJS, so that Azurite can keep track of how big and where chunks of binary data are kept in the extent store. The extent storage is a custom mechanism implemented fully in the Azurite codebase. Essentially byte arrays are written into the store and retrievable again using an extent identifier. Some optimizations are made in Azurite so that multiple blobs of binary content can be collocated in a single extent file. Azurite tries to write up to 64 MB of content into an extent before starting a new one. One of these files may have many blobs or queue messages inside of it. To optimize deletions from the extent store, data is not removed immediately from an extent. Instead, the extent is simply unlinked in the metadata store and later a garbage collection process runs to identify and remove orphan extents. This GC process is separate from the GC built into the Node.js for normal objects. The blob extent GC runs every 10 minutes and the queue extent GC runs every 1 minute in order to free up disk space.
In short, blob and queue operations that add, remove, update, or read data require several in-memory LokiJS operations and at least one disk operation to complete. Table operations require only in-memory LokiJS operations to complete (not needing to read or write any extents). There are background processes to maintain the disk state for both LokiJS and extents.
It’s important to note that you can still lose data when the default disk-based persistence is used. The process can crash after accepting data into LokiJS but before it is persisted to disk. Or you can lose the disk-based persistence due to human error or disk failure. And on and on. If you want production-grade Azure Storage persistence, you should use Azure!
This disk-based persistence is all fine if you want to keep the Azurite data around for some extended period. But this is all wasted effort if you’re just running some integration tests against storage and don’t need the data to be persisted after the tests are complete!
Memory-based persistence (new behavior)
After coming to an understanding of how Azurite uses disk-based persistence, I opened the PR Azure/Azurite#2228 to optionally disable the LokiJS disk persistence and move the extent store entirely into memory. I worked with a member of the Azurite team who was very receptive to the change and provided awesome feedback on my code change. After several iterations and a Teams call, it was merged for the 3.28.0 release.
As part of the process, I wrote a design document that describes my motivation: Add an option to use only in-memory persistence. I also added a whole section to the Azurite README about this new option: Use in-memory storage.
To use the feature, first check that you’re on the latest version of Azurite. If you’re using Azurite from npm, you can
run azurite --version or npx azurite --version. If you’re running Azurite as a VS Code extension, you can click on
Azurite in your extension list and check the top of the extension details page:

If you’re on version 3.28.0 or later, you can enable in-memory persistence. Note that enabling this option will not move existing disk-based data into memory and will not modify that existing disk-based data at all. Also, and this is critical to understand, when the Azurite process ends, all data stored in-memory will be lost. This is by design for the scenario I described above, but it’s important to understand. Don’t go storing business-critical data in Azurite with in-memory mode!
There are two ways to turn on this new feature.
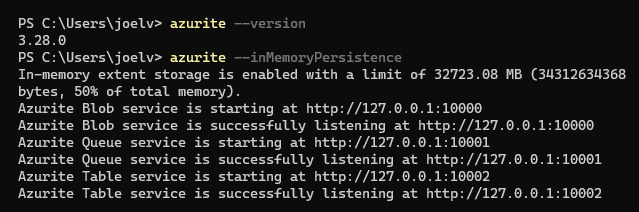
Azurite on the CLI (npm, Docker): specify the --inMemoryPersistence option.
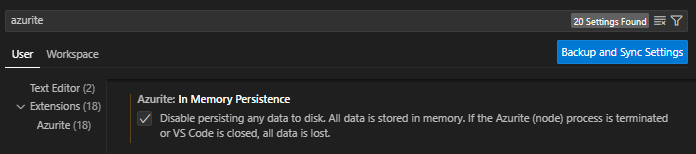
Azurite in VS Code: enable the azurite.inMemoryPersistence option either via JSON or in the UI.
After enabling the setting in VS Code, you’ll need to start one or more of the Azurite services via the command palette or click one of the service names in the bottom status code.
When running from the CLI, you’ll know the option is working because the first line of output will be like this:
In-memory extent storage is enabled with a limit of 7990.73 MB (8378888192 bytes, 50% of total memory).
In addition to the new in-memory persistence option, there is another option to limit the amount of bytes allowed for
the in-memory extent store. Blobs, for example, can take up a lot of space and you may not want Azurite to eat up all of
your machine’s RAM storing blob or queue content! By default, the extent store is limited to 50% of the total physical
memory on the machine (per Node.js’s os.totalmem() API). This can be
overridden with the --extentMemoryLimit <size limit in MB> option from the CLI or azurite.extentMemoryLimit VS Code
setting.
Enjoy the new option!